
티스토리 뷰
이번 포스팅에서는 가장 많이 쓰이는 자료구조중 하나인 스택에 대해서 알아보고 구현해 보도록 하겠다.
우선 사전적인 정의를 한번 보고오도록 하겠다.
https://ko.wikipedia.org/wiki/%EC%8A%A4%ED%83%9D
스택 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 스택의 구조 스택(stack)은 제한적으로 접근할 수 있는 나열 구조이다. 그 접근 방법은 언제나 목록의 끝에서만 일어난다. 끝먼저내기 목록(Pushdown list)이라고도
ko.wikipedia.org
사전적인 정의에 대해서는 굳이 다시 옮겨 적진 않겠다.
중점적으로 볼것은 FILO , LIFO 구조 라는것이다.
fisrt in last out, last in first out 즉 선입후출(先入後出) , 후입선출(後入先出)의 구조를 갖는 자료구조를 말한다.
컴퓨터 구조도 이런 스택 구조로 되어있고 또 그간 무수한 알고리즘 풀이에서 사용해왔던 재귀적인 풀이도
사실 이런 스택구조의 원리를 이용하는 만큼 사실 정말 많이 쓰이는 자료구조이니 만큼
컴퓨터과학에 대해 공부하는 사람이라면 반드시 한번은 구현 해보아야 할 자료구조라 생각이 든다.
그럼 다시 본론으로 넘어가서 이런 스택의 연산으로는 어떤 것들이 있는가 알아보자면 다음과 같다.
- top() : 스택의 가장 윗 데이터를 반환한다.
- pop() : 스택의 가장 윗 데이터를 삭제한다.
- push() : 스택의 가장 윗 데이터로 top이 가리키는 자리 위에 메모리를 생성후 데이터를 삽입한다.
- empty() : 스택이 비었다면 1을 반환하고 그렇지 않다면 0을 반환한다.
단순히 글로만 봐서는 무슨소리인가 싶을수도 있다.
그럼 그림과 함께 자세한 설명을 해보겠다.
우선 비어있는 스택을 다음과 같은 그림으로 표현 해보도록 하겠다.

현재 스택이 비어있으므로 우선 데이터를 삽입하는 연산인 push 연산을 해보겠다.
정의에서보면 스택의 가장 윗 데이터로 top이 가리키는 자리 위에 메모리를 생성후 데이터를 삽입한다.
라고 되어있다.
따라서 이때 데이터1을 삽입한다면 현재 top의 상위의 위치로 데이터가 삽입되고 top은 삽입된 데이터를 가리킨다.
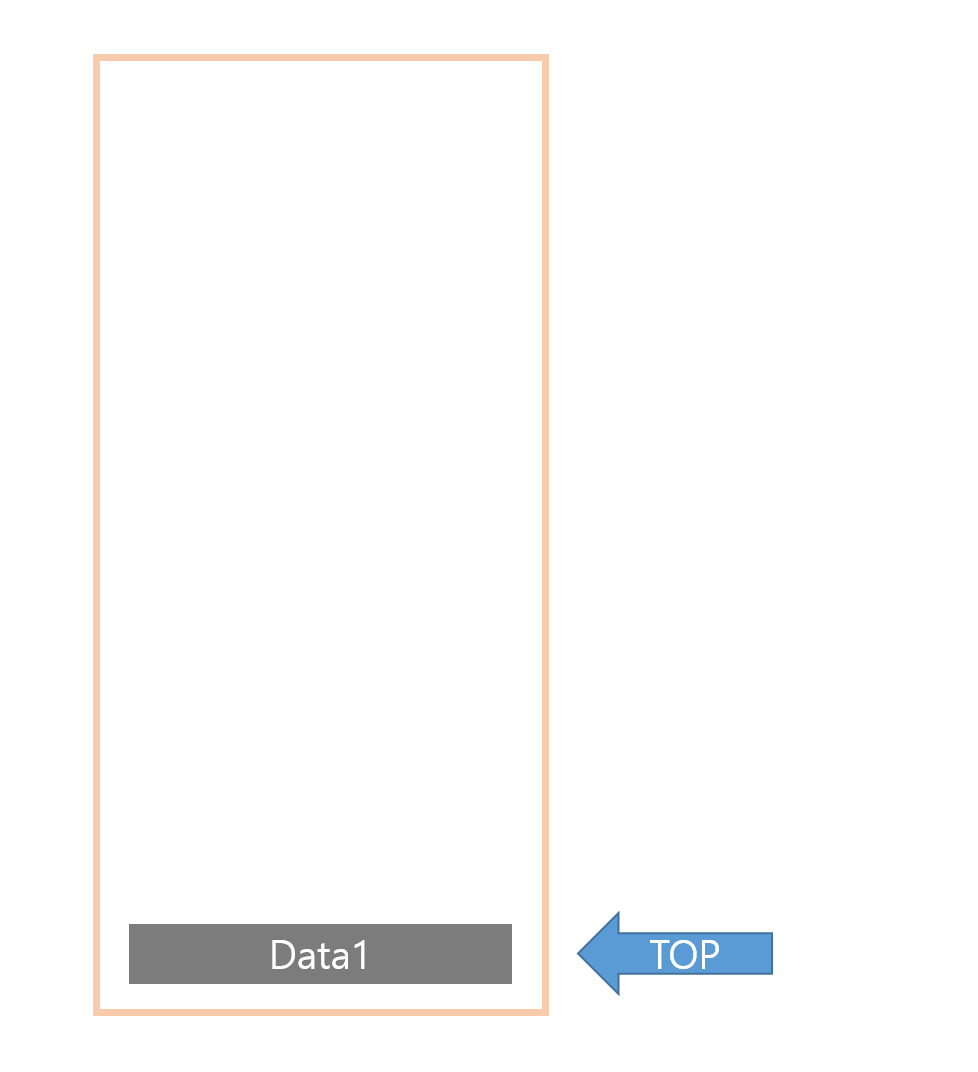
이제 한번더 push 연산을 진행해보겠다.
data2 를 push 한다면 현재 top에 해당하는 데이터가 존재하므로 그 위의 공간에 메모리를 할당후
데이터를 삽입하게 된다.

이제 empty 연산시 현재 스택의 top을 확인해보고 Data2가 있음을 확인하고 0(false)을 반환할것이고
top 연산시에는 Data2 를 반환할것이다.
이때 pop 연산시에는 현재 스택의 가장 위 데이터를 삭제한다라고 되어있으므로
data2는 삭제되고 top은 data1을 가리킬것이다.

연달아 pop연산을 수행한다면 data1을 제거하고 스택은 비어있는 상태가 될것이다.

이 상태에서 empty 연산을 수행한다면 스택이 비어있으므로 1(true)을 반환할것이다.
이제 스택의 정의와 연산에 대해 알아보았으니 구현을 해보도록 하겠다.
우선 어떤 타입의 데이터를 저장할 스택인지 알수 없으니 참조타입의 모든 데이터를 받을수 있도록
제네릭 클래스로 생성하도록 하겠다.
public class StackImpl <T>{
}
제네릭에 대해선 간단히 설명하자면 데이터 형식에 의존하지 않는
어떤 형식의 자료형에 대해서든 자유롭게 정의해서 사용이 가능하단 특징이 있다는 것만 알아두고 넘어가도록 한다.
혹여 자세히 알고 싶다면 다음 링크를 참조하면 된다.
https://0bliviat3.tistory.com/52
제네릭(Generic)
왜 제네릭을 사용하는가? 컴파일시 강한 타입체크를 할 수 있다. 제네릭 타입 선언을 통해 실행 전 컴파일시 미리 타입을 강하게 체크해 에러를 사전에 방지할수 있다. 불필요한 형변환을 줄일
0bliviat3.tistory.com
멤버변수로는 현재 스택의 TOP을 의미하는 변수 top, 그리고 배열을 사용해 구현할 것이므로 기본 배열의
사이즈를 의미하는 변수 size, 마지막으로 스택을 구현할 배열을 선언하도록 하겠다.
private int top = -1;
private int size = 10;
private T[] stack;
이런 자원들은 외부에서 접근이 불가하도록 접근제어자 private를 걸어 보호해준다.
다음으론 생성자 부분이다.
제네릭 타입의 배열은 생성이 불가하므로 형변환을 통해 생성될수있도록 했다.
@SuppressWarnings("unchecked")
public StackImpl() {
stack = (T[]) new Object[size];
}
이제 연산자 부분에 대해 메소드로 정의를 해보도록 하겠다.
먼저 top 연산자 이다.
스택이 비어있는 순간을 의미하는 -1인 경우 null을 리턴, 아니라면 현재의 top에 해당하는 stack의 값을 반환하도록 한다.
public T top() {
if(top == -1) return null;
return stack[top];
}
다음은 empty 연산자이다.
스택이 비어있는 경우 즉 top() 메소드가 null을 리턴하는 경우 true 리턴,
아니라면 false를 리턴하도록 한다.
public boolean empty() {
if(top() == null) return true;
return false;
}
다음으론 현재 스택의 길이를 반환하는 size 메소드이다.
현재 top에 +1 을 함으로서 길이 0부터 size까지 정수로 리턴이 가능하게끔 한다.
public int size() {
return top + 1;
}
다음은 pop 연산자이다.
현재 스택의 top에 해당하는 값을 반환하면서 삭제해야 하므로
그냥 단순히 top을 한칸 앞으로 땡겨주면서 현재 top 값을 반환해준다.
접근제어자로 인해 현재 배열 자체엔 접근이 불가하기 때문이다.
또 스택이 비어있는 경우엔 스택이 비어있단 문구를 출력해주고 null값을 리턴해준다.
public T pop() {
if(!empty()) {
return stack[top--];
}
System.out.println("stack is empty");
return null;
}
push 연산자 구현에 앞서 가변배열의 길이를 늘리는 메소드 먼저 작성하도록 하겠다.
초기 배열의 경우 길이를 10으로 지정해 주었으나 반복적인 push 연산이 발생한다면 배열의 길이를 초과하는
경우가 발생할수 있으므로 이 경우 배열의 길이를 두배로 늘리고 현재 스택의 값을 모두 복사 해주도록 한다.
@SuppressWarnings("unchecked")
private void cloneStack() {
T[] temp = (T[]) new Object[size << 1];
for(int i = 0; i < size; i++) {
temp[i] = stack[i];
}
stack = temp;
size*=2;
}
마지막으로 push 연산자의 구현이다.
먼저 배열의 길이가 충분하지 않다면 배열의 길이를 늘려주는 메소드를 호출하고
현재 top보다 위의 공간에 값을 저장하도록 한다.
public void push(T insert) {
if(size() == size) {
cloneStack();
}
stack[++top] = insert;
}
다음은 코드의 전문이다.
public class StackImpl <T>{
private int top = -1;
private int size = 10;
private T[] stack;
@SuppressWarnings("unchecked")
public StackImpl() {
stack = (T[]) new Object[size];
}
public T top() {
if(top == -1) return null;
return stack[top];
}
public boolean empty() {
if(top() == null) return true;
return false;
}
public int size() {
return top + 1;
}
public T pop() {
if(!empty()) {
return stack[top--];
}
System.out.println("stack is empty");
return null;
}
public void push(T insert) {
if(size() == size) {
cloneStack();
}
stack[++top] = insert;
}
@SuppressWarnings("unchecked")
private void cloneStack() {
T[] temp = (T[]) new Object[size << 1];
for(int i = 0; i < size; i++) {
temp[i] = stack[i];
}
stack = temp;
size*=2;
}
}
이제 구현이 정확하게 되었는가 테스트 해보도록 하겠다.
현재 구현한 스택은 제네릭 클래스로 구현을 했기 때문에 참조타입의 모든 자료형이 저장 가능하므로
아이스크림 통이라고 테마를 잡고 아이스크림통에 넣는 각 아이스크림의 정보를 저장한다라고 가정을 해보도록 하겠다.
우선 아이스크림에 대한 정보를 저장할 클래스를 간단히 만들어주겠다.
아이스크림의 이름, 그리고 성분을 저장하는 클래스이다.
public class IceCream {
private String name;
private String kcal;
private String Na;
private String sugars;
private String saturatedFat;
private String protein;
private String caffeine;
IceCream(String name, String kcal, String Na, String sugars, String saturatedFat, String protein, String caffeine){
this.name = name;
this.kcal = kcal;
this.Na = Na;
this.sugars = sugars;
this.saturatedFat = saturatedFat;
this.protein = protein;
this.caffeine = caffeine;
}
void prt(){
StringBuilder sb = new StringBuilder();
sb.append("제품명 : ").append(name).append('\n');
sb.append("칼로리 : ").append(kcal).append('\n');
sb.append("나트륨 : ").append(Na).append('\n');
sb.append("당류 : ").append(sugars).append('\n');
sb.append("포화지방 : ").append(saturatedFat).append('\n');
sb.append("단백질 : ").append(protein).append('\n');
sb.append("카페인 : ").append(caffeine).append('\n');
System.out.print(sb);
}
}
간단히 하려했는데 일이 좀 커진 느낌이 들지만, 기왕하는거 제대로 하려고
베스킨라빈스 아이스크림 성분표를 긁어와 csv 파일로 만들어 List로 저장해 주었다.

csv 파일 입력)
Charset.forName("UTF-8");
BufferedReader in = Files.newBufferedReader(Paths.get("/tmp/icecream.csv"));
String line = null;
StringTokenizer st;
String[] data = new String[7];
List<IceCream> iceList = new ArrayList<>();
in.readLine();
while((line = in.readLine()) != null) {
st = new StringTokenizer(line,",");
for(int i = 0; i < 7; i++) {
data[i] = st.nextToken();
}
iceList.add(new IceCream(data[0],data[1],data[2],data[3],data[4],data[5],data[6]));
}
in.close();
이제 스택을 사용한 연산을 해보도록 하겠다.
먼전 아까 정의해둔 StackImpl 객체를 만들어준다.
StackImpl<IceCream> iceCreamStack = new StackImpl<>();
리스트에 저장해둔 아이스크림을 그냥 반복문을 사용해 4개만 넣어주도록 하겠다.
이때 어떤 아이스크림 순서로 들어갔는지 확인 하기 위해 들어가는 순서대로 출력도 해주도록 하겠다.

아무래도 그냥 긁어온것이다 보니 아이스크림 아닌 메뉴도 보이긴 하지만 신경쓰지 않고 그냥 진행하겠다.
출력된것을 보면 슈팅스타, 아메핫, 아메핫 라지, 아메아이스 순으로 삽입된것을 확인할수 있다.
이제 top 연산을 통해 현재의 top 이 어떤 메뉴를 가리키는지 확인 해보겠다.

가장 마지막에 삽입되었던 아메 아이스를 가리키고 있는 것을 확인할수 있다.
empty 연산에서는 현재 스택은 비어있지 않으니 false인것 또한 확인이 가능하다

현재 삽입된 데이터가 4개이니 size 메소드를 통해서 스택의 크기 또한 4로 나오는것을 확인할수 있다.

이번엔 16개의 데이터를 삽입하고 가변배열 메소드가 정상 동작하는지 확인해보겠다.

스택의 크기가 16인것으로 보아 초기 설정해준 10에서 자동으로 크기가 증가했음을 확인 할 수 있다.
다시 4개를 삽입한 스택으로 돌아가 이번엔 스택이 비워질때까지 차례로 pop 연산하면서 동시에 출력해보겠다.
아까 슈팅스타, 아메핫, 아메핫 라지, 아메아이스 순으로 삽입이 되었으니
올바른 후입선출의 스택구조를 구현했다면
아메아이스, 아메핫 라지, 아메핫, 슈팅스타 순으로 출력될것이다.

예상 순서대로 잘 출력 되는것을 확인할수 있다.
이후 한번더 pop 연산을 수행한다면 아까 만들어 두었던 스택이 비었다는 문구를 출력해주는것을 확인 할 수 있다.

마지막으로 empty 연산을 수행한다면

true 로 스택이 비어있는것 또한 정확히 출력되는것을 확인 할 수 있다.
스택은 구현 자체도 어렵지 않고 개념 자체도 어렵지 않으나 가장 많이 사용되는 자료구조 중 하나이니
반드시 숙지해서 활용할수 있도록 하는것이 좋다.
'알고리즘 > 구현' 카테고리의 다른 글
| 유클리드 호제법(JAVA) (0) | 2023.09.17 |
|---|---|
| [자료구조] 이진 트리와 순회의 구현(JAVA) (1) | 2023.09.16 |
| [자료구조] 큐(Queue)의 구현(JAVA) (0) | 2023.09.13 |
| BFS(너비 우선 탐색) 구현 (JAVA) (0) | 2023.09.04 |
| DFS(깊이 우선 탐색) 인접 행렬 구현 (JAVA) (0) | 2023.09.03 |